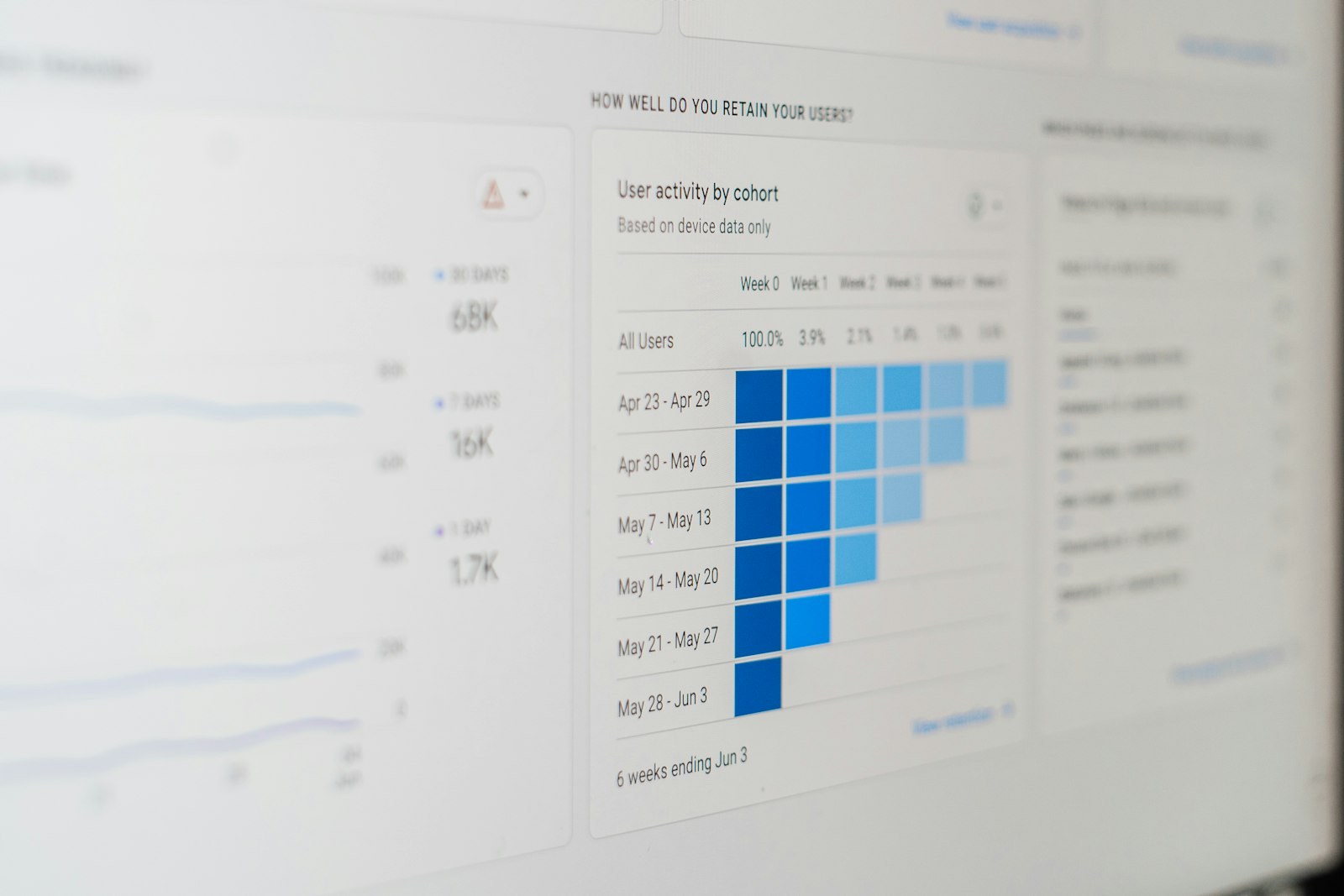
Selon MIT Sloan 2024, la qualité des données explique 64 % de la variance de performance IA. Méthode en six étapes pour mesurer et améliorer les six dimensions de qualité (exactitude, complétude, cohérence, unicité, fraîcheur, traçabilité) avec ROI à moins de 12 mois.
Selon l'observatoire MIT Sloan Data Quality Survey 2024 sur 1 842 entreprises, la qualité des données utilisées par les modèles IA explique 64 % de la variance des performances IA en production. Selon Gartner Data & Analytics 2024, le coût moyen de la mauvaise qualité de données pour une PME est de 9 à 15 % du chiffre d'affaires annuel (décisions erronées, ressaisies, opportunités manquées, conformité dégradée). Pour un dirigeant de PME, le constat est documenté : investir dans la qualité des données est le levier IA à plus fort effet, plus important que l'investissement dans les modèles ou les outils. Cet article décrit la méthode en six étapes pour structurer la qualité des données en moins de huit semaines.
Pourquoi la qualité des données détermine la performance IA
Quatre mécanismes structurels. Premier mécanisme : « garbage in, garbage out » principe fondamental. Une IA entraînée ou alimentée par des données de mauvaise qualité (erreurs, doublons, incohérences, valeurs manquantes) produit des sorties de mauvaise qualité. Aucune sophistication algorithmique ne compense des données dégradées. Deuxième mécanisme : la diffusion des erreurs. Les erreurs dans les données se propagent en cascade à travers tous les cas d'usage IA, créant un effet multiplicateur. Une PME avec 10 cas d'usage IA et 5 % de données erronées subit potentiellement 40 à 60 incidents par mois. Troisième mécanisme : l'érosion progressive de la confiance. Les collaborateurs et clients perdent progressivement confiance dans une IA produisant des résultats inconsistants ou erronés, ce qui dégrade l'adoption et le ROI. Quatrième mécanisme : l'amplification des biais. Les biais présents dans les données sont amplifiés par les modèles IA, ce qui crée des risques réglementaires (AI Act) et réputationnels significatifs.
Notre lecture est la suivante. Pour une PME, la stratégie data n'est pas un sujet IT mais un fondamental stratégique. Concrètement : cartographier les sources de données, mesurer la qualité actuelle, identifier les écarts critiques, structurer les contrôles et processus, former les équipes, mesurer en continu. Cette discipline divise par 4 à 6 les incidents IA et améliore drastiquement le ROI des programmes IA.
Les six dimensions de la qualité des données à maîtriser
Dimension 1 : l'exactitude
Les données reflètent-elles fidèlement la réalité ? Exemples d'écarts typiques : adresses obsolètes, e-mails non vérifiés, données financières non actualisées, dates erronées. Mesure : % de données correctes vérifiées par échantillonnage. Cible PME mature : > 95 %.
Dimension 2 : la complétude
Toutes les données nécessaires sont-elles présentes ? Exemples : fiches clients sans secteur d'activité, factures sans référence projet, contrats sans date d'échéance. Mesure : % de fiches avec tous les champs critiques renseignés. Cible : > 90 %.
Dimension 3 : la cohérence
Les données sont-elles cohérentes entre les différentes sources et bases ? Exemples : client avec deux fiches dans CRM et ERP avec adresses différentes, projet avec budget différent dans BPM et finance. Mesure : % de données alignées entre sources. Cible : > 95 %.
Dimension 4 : l'unicité (déduplication)
Y a-t-il des doublons ou triplons ? Exemples : clients avec 3 fiches différentes, fournisseurs avec variantes orthographiques, produits avec références multiples. Mesure : % de doublons identifiés sur l'ensemble. Cible : < 3 %.
Dimension 5 : la fraîcheur
Les données sont-elles à jour ? Exemples : contacts non mis à jour depuis 3 ans, prix produits obsolètes, conditions commerciales périmées. Mesure : % de données actualisées dans la fenêtre attendue. Cible : > 90 %.
Dimension 6 : la traçabilité
Connaît-on l'origine et l'historique des données ? Exemples : source, date de création, modifications successives, validation. Critique pour audit RGPD et AI Act. Mesure : % de données avec traçabilité complète. Cible : > 90 %.
Méthode en six étapes pour structurer en huit semaines
1. Cartographier les sources de données et leur criticité
Trois axes d'analyse. Axe 1 (sources) : identifier toutes les sources de données utilisées (CRM, ERP, BPM, outils marketing, sources externes, fichiers Excel, e-mails). Axe 2 (criticité) : classer chaque source selon son impact sur les décisions et les cas d'usage IA (critique, élevée, modérée, faible). Axe 3 (volumétrie) : quantifier le volume de données par source. Cette cartographie révèle typiquement 8 à 20 sources critiques par PME.
2. Mesurer la qualité actuelle des sources critiques
Trois actions. Action 1 (audit qualité) : échantillonner 100 à 500 enregistrements par source critique et mesurer les 6 dimensions de qualité. Action 2 (synthèse par source) : calculer un score qualité global par source (moyenne pondérée des 6 dimensions). Action 3 (identification des écarts critiques) : identifier les sources avec score < 70 % à prioriser pour amélioration immédiate.
3. Structurer les actions de remédiation par priorité
Trois priorités typiques. Priorité 1 (sources critiques < 60 %) : action immédiate avec remédiation manuelle + structuration des contrôles. Priorité 2 (sources critiques 60-80 %) : action progressive avec automatisation des contrôles + sensibilisation des équipes. Priorité 3 (sources critiques > 80 %) : maintien et amélioration continue avec mesure régulière.
4. Mettre en place les contrôles automatiques et l'enrichissement IA
Cinq contrôles essentiels. Contrôle 1 (validation à la saisie) : contrôles automatiques de format, cohérence, complétude à la saisie. Contrôle 2 (déduplication IA) : déduplication automatique par IA détectant les variantes orthographiques, les fusions probables. Contrôle 3 (enrichissement automatique) : enrichissement des données depuis sources externes (annuaires entreprises, données géographiques, données financières publiques). Contrôle 4 (détection des anomalies IA) : détection automatique des incohérences, valeurs aberrantes, doublons résiduels. Contrôle 5 (révision périodique) : campagnes périodiques de revue qualité (trimestrielles ou semestrielles selon la criticité).
5. Structurer la gouvernance et former les équipes
Quatre éléments. Premier : désigner un responsable qualité données (DAF, DSI ou référent dédié selon la taille). Deuxième : formaliser les politiques qualité (responsabilités, contrôles, escalades). Troisième : structurer un comité qualité données trimestriel. Quatrième : former les équipes à la saisie de qualité, aux contrôles, aux bonnes pratiques (4 à 8 heures par utilisateur).
6. Mesurer et améliorer en continu
Six indicateurs critiques. Premier : score qualité global par source critique (cible > 85 %). Deuxième : taux de complétude des champs critiques (cible > 90 %). Troisième : taux de doublons (cible < 3 %). Quatrième : fraîcheur des données (cible > 90 % actualisées). Cinquième : nombre d'incidents IA liés à la qualité données (cible < 2/mois). Sixième : ROI du programme qualité données (cible < 12 mois grâce à la réduction des erreurs et l'amélioration IA).
Les sept cas d'usage IA bénéficiant le plus de la qualité données
Cas 1 : scoring prédictif commercial
Une PME passant de 70 % à 92 % de qualité données voit la précision du scoring passer de 62 % à 86 %, soit +24 points qui transforment la performance commerciale.
Cas 2 : prédiction de trésorerie
L'amélioration qualité données financières (passage de 75 % à 93 %) améliore la précision de la prédiction de trésorerie à 3 mois de 68 % à 88 %.
Cas 3 : détection des anomalies et fraudes
L'amélioration qualité données opérationnelles divise par 2-3 les faux positifs et augmente le taux de détection des vraies anomalies.
Cas 4 : génération de contenus personnalisés
La qualité données clients (complétude, fraîcheur, cohérence) conditionne directement la qualité de la personnalisation des contenus marketing.
Cas 5 : support client conversationnel
Un chatbot alimenté par une base documentaire propre et structurée résout 65-80 % des demandes en autonomie vs 25-45 % avec données dégradées.
Cas 6 : prédiction de qualité et de défaillances industrielles
L'amélioration qualité données industrielles (capteurs, opérations) divise par 2-3 les défaillances qualité grâce à des prédictions plus fiables.
Cas 7 : rapports et synthèses dirigeantes
L'amélioration qualité données globale élimine 70-85 % des incohérences et erreurs dans les rapports et synthèses IA destinés aux dirigeants.
Indicateurs à suivre dès le premier trimestre
- Cartographie des sources de données critiques — cible 100 %.
- Score qualité moyen par source critique — cible > 85 %.
- Taux de complétude des champs critiques — cible > 90 %.
- Taux de doublons — cible < 3 %.
- Fraîcheur des données — cible > 90 %.
- Nombre d'incidents IA liés à la qualité — cible < 2/mois.
- ROI cumulé du programme — cible < 12 mois.
Cas pratique : PME B2C retail, 67 collaborateurs
Une PME française de retail multicanal (5 magasins + boutique en ligne) avec 67 collaborateurs et 14,8 M€ de chiffre d'affaires, avait déployé 5 cas d'usage IA en 2023 (scoring clients, prédiction stocks, chatbot, segmentation marketing, détection anomalies) avec adoption décevante (32 %) et ROI marginal. Diagnostic en 2024 : qualité données médiocre (score moyen 64 %, 18 % de doublons clients, 35 % de fiches incomplètes).
Application de la méthode sur 8 semaines avec accompagnement d'un consultant qualité données (14 k€) : cartographie de 12 sources de données critiques, audit qualité avec mesure des 6 dimensions, identification de 3 sources critiques < 60 % (CRM, ERP, base stocks), remédiation manuelle (campægne de nettoyage avec 2 personnes pendant 3 semaines), mise en place de contrôles automatiques à la saisie + déduplication IA + enrichissement automatique depuis sources externes, formation 6 heures par utilisateur, structuration gouvernance avec responsable qualité données (DAF mi-temps). Résultats à 12 mois : score qualité global passé de 64 % à 91 %, doublons clients passés de 18 à 1,8 %, complétude fiches clients passée de 65 à 94 %, performance des 5 cas d'usage IA améliorée significativement (taux d'adoption monté à 84 %, précision scoring passée de 58 à 84 %, faux positifs détection anomalies divisés par 3), gain commercial estimé +280 k€/an grâce à scoring fiable, économie ressaisies 95 k€/an. Coût total programme : 38 k€ initial + 22 k€/an récurrent, ROI à 1,5 mois.
Comment OperaFlux peut accompagner cette structuration
OperaFlux ne se substitue pas à un cabinet conseil qualité données, à un éditeur Master Data Management spécialisé, ou aux experts internes en gouvernance data. Le rôle de la plateforme se concentre sur la consolidation des données et les contrôles intégrés.
- CRM — comprendre vos clients, gagner plus de deals : données clients consolidées avec contrôles à la saisie, déduplication IA native, enrichissement automatique, traçabilité auditable.
- ERP — du document à la trésorerie, sans labyrinthe : données financières et opérationnelles consolidées avec validations natives, rapprochements automatiques.
- BPM — quand tout avance tout seul, sans vous perdre : workflows de qualité données (revue, validation, enrichissement) avec Human-in-the-loop natif.
- ESG — parler financier même quand on parle carbone : cockpit qualité données trimestriel avec scores par source, taux de doublons, complétude, fraîcheur, restitution dirigeant.
- Sécurité européenne souveraine : hébergement français qualifié SecNumCloud, chiffrement, conformité RGPD by design, traçabilité auditable des données.
Nous assumons les limites du produit. Les démarches très avancées de Master Data Management (MDM) et de gouvernance data complexes relèvent de solutions verticales spécialisées. OperaFlux fournit le socle consolidé pour les besoins courants de la PME. Comparez les conditions sur la page tarifs ou consultez le détail des modules sur la page fonctionnalités.
Questions fréquentes des dirigeants de PME
Combien de temps consacrer à la qualité données vs les cas d'usage IA ?
Trois logiques. Logique 1 (PME data-faible < 70 % qualité) : privilégier d'abord la qualité (70 % du temps) avant de déployer des cas d'usage IA. Logique 2 (PME data-moyenne 70-85 %) : équilibre 40-60 entre qualité et cas d'usage. Logique 3 (PME data-mature > 85 %) : privilégier les cas d'usage IA (70 %) avec maintien qualité (30 %). Un cas d'usage IA déployé sur des données dégradées génère typiquement -50 à -70 % de ROI vs le potentiel.
Faut-il un Chief Data Officer (CDO) en PME ?
Trois logiques selon la taille. PME < 50 collaborateurs : pas de CDO dédié, le DAF ou le DSI assure le rôle à temps partiel. PME 50 à 150 collaborateurs : référent qualité données à mi-temps (typiquement DAF) avec support consultant ponctuel. PME > 150 collaborateurs : CDO à temps plein avec équipe de 2-3 personnes. Quel que soit le format, l'engagement explicite du dirigeant est essentiel.
Comment financer un programme qualité données ?
Trois sources de financement. Source 1 (économies internes) : le programme s'autofinance typiquement à partir de M+6-9 grâce aux économies de ressaisies et aux gains commerciaux. Source 2 (BPI France et Régions) : certains dispositifs financent les projets de transformation numérique incluant la qualité données. Source 3 (Crédit Impôt Recherche) : pour les développements spécifiques liés à la qualité données (algorithmes, automatisations).
Quelles certifications visent les PME data-matures ?
Trois certifications structurantes. Certification 1 (ISO 27001) : management de la sécurité de l'information, fortement liée à la qualité données. Certification 2 (ISO 8000) : qualité des données entreprise, plus spécifique. Certification 3 (Privacy by Design) : démarche RGPD avancée. Pour une PME 30-150 collaborateurs, l'ISO 27001 est typiquement la plus pertinente (15-50 k€ initial, 8-25 k€/an récurrent).
Comment gérer la résistance des équipes face aux contrôles qualité ?
Cinq leviers. Levier 1 (communication transparente) : expliquer l'impact des erreurs de qualité sur les cas d'usage IA et donc sur la performance globale. Levier 2 (outils ergonomiques) : privilégier des outils où les contrôles sont naturels et peu intrusifs (validation à la saisie, suggestions IA). Levier 3 (valorisation) : intégrer la qualité données dans les évaluations et politiques salariales. Levier 4 (formation) : 4 à 8 heures par utilisateur sur les bonnes pratiques de saisie. Levier 5 (responsabilisation) : chaque collaborateur est responsable de la qualité des données qu'il manipule.
Aller plus loin
Si vos cas d'usage IA performent en dessous des attentes, si vous avez des doublons clients ou des données obsolètes significatifs, ou si vous voulez accélérer le ROI de votre programme IA, le coût d'inaction sur un trimestre dépasse aujourd'hui celui d'un cadrage structuré. Comparez les conditions sur la page tarifs ou réservez 30 minutes avec un expert OperaFlux pour cadrer votre programme qualité données.